


Next: 1.5 Clinical overview of
Up: 1.4 Data Organization
Previous: 1.4.3 Subject ID -
Contents
1.4.4 De-identification of patients' data
The process for the removal of protected health information
(PHI) in the the MIMIC II
database is fully described in our publication [6]
which can be freely accessed at the following URL:
http://www.biomedcentral.com/1472-6947/8/32 A labeled subset of
the data, together with a public version of the code can be found on
PhysioNet at: http://www.physionet.org/physiotools/deid/.
Figure 1.5 illustrates the de-identification process.
Briefly, the salient points for the user of our database are:
- All dates were shifted
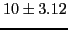 years into the future. The
date shift for each patient was independently assigned by sampling
from a uniform distribution.
years into the future. The
date shift for each patient was independently assigned by sampling
from a uniform distribution.
- All ICU dates for a given patient were shifted by the same
amount to preserve inter-admission time gaps.
- The day of the week and season of the year were preserved.
- Patients who turned 90 during one of their admissions have been
removed form the database. They may be included at a later date.
- Patients older than 89 years at the date of first admission have
had their dates of birth shifted so that they appear to be 200 years
old at the time of their first admission. They will therefore show
up as extreme outliers. Their inter-admission timings are still
preserved.
- Since date shifts were randomly assigned, longitudinal studies
that involve changes in patient care practices over time cannot be
supported by the fully de-identified data. Support for studies that
require the year of admission will be considered on an individual
basis by special request.
- All HIPAA-defined types of PHI were removed, plus care-giver and
hospital-specific identifiers.
- The algorithm achieved an overall recall of 0.967 and precision
of 0.749 on a `gold standard' test corpus, which out-performs a
single human de-identifier and performs at least as well as a
consensus of two human de-identifiers [6].
Examples of a de-identified nursing progress note and discharge
summary can be found in figures 1.6 and
1.7 respectively. Note that a few of the
de-identified sections of the nursing note are false positives, and a
small fraction of the clinical information may have been
lost. However, all dates and names (the only PHI in this document)
were caught by our algorithm. Note also the the high prevalence of
abbreviations such as S/0 (sign out),
D/C'd (discontinued, or discharged), Neo (neosynephrine), NSR (normal
sinus rhythm), F/E (fluid and electrolytes), GI (gastrointestinal),
HEME (hematology), ID (infectious disease), A (assessment), P (plan),
etc. Note also the low degree of structure in the nursing note,
broken into a few categories; S/O, F/E, NEURO, GI, HEME, ID,
RESP, SKIN, ACCESS, SOCIAL, A, and P. The boldface type has
been added to this figure to highlight these categories, but is not
available in the notes.
Next: 1.5 Clinical overview of
Up: 1.4 Data Organization
Previous: 1.4.3 Subject ID -
Contents
djscott
2010-08-24